2 Research Data Management
2.1 What is research data management?
Research data management (RDM) involves the organization, storage, preservation, and dissemination of research study data (Bordelon n.d.b). Research study data includes materials generated or collected throughout a research process (National Endowment for the Humanities 2018). As you can imagine, this broad definition includes much more than just the management of digital datasets. It also includes physical files, documentation, artifacts, recordings, and more. RDM is a substantial undertaking that begins long before data is ever collected, during the planning phase, and continues well after a research project ends during the archiving phase.
2.2 Standards
Data management standards refer to rules for how data should be collected, formatted, described, and shared (Borghi and Van Gulick 2022; Koos n.d.). Implementing standards for things such as how variables should be collected and named, which items from common measures should be shared, and how data should be formatted and documented, leads to more findable and usable data within fields and provides the added benefit of allowing researchers to integrate datasets without painstaking work to normalize the data.
Some fields have adopted standards across the research life cycle, such as CDISC standards used by clinical researchers (CDISC n.d.), other fields have adopted standards specifically around metadata, such as the TEI standards used in digital humanities (Burnard 2014) or the ISO 19115 used for geospatial data(Michener 2015), and through grassroots efforts, other fields such as psychology are developing their own standards for things such as data formatting and documentation (Kline 2018) based on the FAIR principles and inspired by the BIDS standard (BIDS-Contributors 2022). Yet, it is common knowledge that there are currently no agreed-upon norms in the field of education research (Institute of Education Sciences n.d.a; Logan and Hart 2023). The rules for how to collect, format, and document data is often left up to each individual team, as long as external compliance requirements are met (Tenopir et al. 2016). However, with a growing interest in open science practices and expanding requirements for federally funded research to make data publicly available (Holdren 2013), data repositories will most likely begin to play a stronger role in promoting standards around data formats and documentation (Borghi and Van Gulick 2022).
2.3 Why care about research data management?
Without current agreed-upon standards in the field, it is important for research teams to develop their own data management standards that apply within and across all of their projects. Developing internal standards, implemented in a reproducible data management workflow, allows practices to be implemented consistently and with fidelity. There are both external pressures and personal reasons to care about developing research data management standards for your projects.
2.3.1 External Reasons
Funder compliance: Any researcher applying for federal funding will be required to submit a data management plan (see Chapter 4) along with their grant proposal (Holdren 2013; Nelson 2022). The contents of these plans may vary slightly across agencies but the shared purpose of these documents is to facilitate good data management practices and to mandate open sharing of data to maximize scientific outputs and benefits to society. Along with this mandatory data sharing policy, comes the incentive to manage your data for the purposes of data sharing (Borghi and Van Gulick 2022).
Journal compliance: Depending on what journal you publish with, providing open access to the data associated with your publication may be a requirement (see PLOS ONE (https://journals.plos.org/plosone/) and AMPPS (https://www.psychologicalscience.org/publications/ampps) as examples). Again, along with data sharing, comes the incentive to manage your data in a thoughtful, responsible, and organized way.
Compliance with mandates: If you are required to submit your research project to the Institutional Review Board (see Chapter 10), the board will review and monitor your data management practices. Concerned with the welfare, rights, and privacy of research participants, your IRB will have rules for how data is managed and stored securely (Filip, n.d.). Data sharing and other legal agreements with research partners will also need to be monitored and honored. Additionally, your organization may have their own institutional data policies that mandate how data must be cared for and secured.
Open science practices: With a growing interest in open science practices, sharing well-managed and documented data helps to build trust in the research process (Renbarger et al. 2022). Sharing data that is curated in a reproducible way is “a strong indicator to fellow researchers of rigor, trustworthiness, and transparency in scientific research” (Alston and Rick (2021), p.2). It also allows others to replicate and learn from your work, validate your results to strengthen evidence, as well as potentially catch errors in your work, preventing decisions being made based on incorrect data (Alston and Rick 2021). Sharing your data with sufficient documentation and standardized metadata can also lead to more collaboration and greater impact as collaborators are able to access and understand your data with ease (Borghi and Van Gulick 2022; Cowles n.d.; Eaker 2016).
Data management is a matter of ethics: In education research we are often collecting data from human participants, and as a result, data management is an ethical issue. It is important to consider the environmental, social, cultural, historical, and political context of the data we are collecting (Alexander 2023). When managing data we are often making human decisions about how to collect, organize, and clean data, and in this process we need to be aware of our biases that may affect equitable representation in our datasets. For instance, how we choose to collect the categories of family relationships, or how we choose to recode or collapse categories of race or gender are just a few examples of ways we may potentially bias our datasets based on our personal lenses.
The process of de-identifying data for data sharing also becomes an ethical issue. Protection of participant identities is not always equally distributed across a dataset. While it may be easy to scrub identifying information for the majority of participants, individuals that represent smaller numbers in the data may still be identifiable and it is important to consider security implications for all participants (McKay Bowen and Snoke 2023).
Last, collecting data from human participants means people are giving their time and energy and entrusting us with their information. Implementing poor data management that leads to irrelevant, unusable, or lost data is a huge disservice to research participants and erodes trust in the research process. It is our responsibility to have well-designed research studies with quality data management and data sharing practices that ensure that participant data remains secure, usable, and true so that their efforts lead to maximum societal benefits (Feeney, Kopper, and Sautmann n.d.).
2.3.2 Personal reasons
Even if you never plan to share your data outside of your research group, there are still many compelling reasons to manage your data in a reproducible and standardized way.
Reduces data curation debt: Taking the time to plan and implement quality data management through the entire research study reduces data curation debt caused by suboptimal data management practices (Butters, Wilson, and Burton 2020). Having poorly collected, managed, or documented data may make your data unusable, either permanently or until errors are corrected. Decreasing or removing this debt reduces the time, energy, and resources spent possibly recollecting data or scrambling at the end of your study to get your data up to acceptable standards.
Facilitates use of your data: Every member of your research team being able to find and understand your project data and documentation is a huge benefit. It allows for the easy use and re-use of your data, and hastens efforts like the publication process (Markowetz 2015). Not having to search around for numbers of consented participants or asking which version of the data they should use allows your team to spend more time analyzing and less time playing detective.
Encourages validation: Implementing reproducible data management practices encourages and allows your team to internally replicate and validate your processes to ensure your outputs are accurate.
Improves continuity: Data management practices such as documentation ensures fidelity of implementation during your project. This includes implementing practices consistently during a longitudinal project, or consistently across sites. It also improves project continuity through staff turnover. Having thoroughly documented procedures allows new staff to pick up right where the former staff member left off and implement the project with fidelity (Borghi and Van Gulick 2021; Cowles n.d.). Furthermore, good data management enables continuity when handing off projects to collaborators or when picking up your own projects after a long hiatus (Markowetz 2015).
Increases efficiency: Documenting and automating data management tasks reduces duplication of efforts for repeating tasks, especially in longitudinal studies.
Upholds research integrity: Errors come in many forms, from both humans and technology(Kovacs, Hoekstra, and Aczel 2021; Strand n.d.). We’ve seen evidence of this in the papers cited as being retracted for “unreliable data” in the blog Retraction Watch (https://retractionwatch.com/). Implementing quality control procedures reduces the chances of errors occurring and allows you to have confidence in your data. Without implementing these practices, your research findings could include extra noise, missing data, or erroneous or misleading results.
Improves data security: Quality data management practices reduce the risk of lost or stolen data, the risk of data becoming corrupted or inaccessible, and the risk of breaking confidentiality agreements.
2.4 Existing Frameworks
Data management does not live in a space all alone. It co-exists with other frameworks that impact how and why data is managed and it is important to be familiar with them as they will provide a foundation for you as you build your data management structures.
2.4.1 FAIR
In 2016, the FAIR Principles (GO FAIR n.d.) were published in Scientific Data, outlining four guiding principles for scientific data management and stewardship. These principles were created to improve and support the reuse of scholarly data, specifically the ability of machines to access and read data, and are the foundation for how all digital data should be publicly shared (Wilkinson et al. 2016). The principles are:
F: Findable
All data should be findable through a persistent identifier and have thorough, searchable metadata. These practices aid in the long-term discovery of information and provide registered citations.
A: Accessible
Users should be able to access your data. This can mean your data is available in a repository or through a request system. At minimum, a user should be able to access the metadata, even if the actual data are not available.
I: Interoperable
Your data and metadata should use standardized vocabularies as well as formats. Both humans and machines should be able to read and interpret your data. Software licenses should not pose a barrier to usage. Data should be available in open formats that can be accessed by any software (e.g., .csv, .txt, .dat).
R: Reusable
In order to provide context for the reuse of your data, your metadata should give insight into data provenance, providing a project description, an overview of the data workflow, as well what authors to cite for appropriate attribution. You should also have clear licensing for data use.
2.4.2 SEER
In addition to the FAIR principles, the SEER principles, developed in 2018 by Institute of Education Sciences (IES), provide Standards for Excellence in Education Research (Institute of Education Sciences n.d.c). While the principles broadly cover the entire life cycle of a research study, they provide context for good data management within an education research study. The SEER principles include:
- Pre-register studies
- Make findings, methods, and data open
- Identify interventions’ core components
- Document treatment implementation and contrast
- Analyze interventions’ costs
- Focus on meaningful outcomes
- Facilitate generalization of study findings
- Support scaling of promising results
2.4.3 Open Science
The concept of Open Science has pushed quality data management to the forefront, bringing visibility to its cause, as well as advances in practices and urgency to implement them. Open Science aims to make scientific research and dissemination accessible for all, making the need for good data management practices absolutely necessary. Open science advocates for transparent and reproducible practices through means such as open data, open analysis, open materials, preregistration, and open access (Dijk, Schatschneider, and Hart 2021). Organizations such as the Center for Open Science (https://www.cos.io), have become a well-known proponents of open science, offering the open science framework (OSF) (Foster and Deardorff 2017) as a tool to promote open science through the entire research life cycle. Furthermore, many education funders have aligned their fundee requirements with these open science practices, such as openly sharing study data and pre-registration of study methods (Institute of Education Sciences n.d.b).
2.5 Terminology
Before moving forward in this book it is important to have a shared understanding of terminology used. Many concepts in education research have multiple terms and can be used interchangeably. Across different institutions, researchers may use all or some of these terms.
Commonly used data management terms
| Terms (Other Terms) | Definitions |
|---|---|
| Anonymous Data | Identifying information that was never collected. This data can not be linked across time or measures. |
| Append | Stacking datasets on top of each other (matching variables). |
| Archive | The transfer of data to a facility, such as a repository, that preserves and stores data long-term. |
| Attrition | The loss of study units from the sample, often seen in longitudinal studies |
| Clean data (processed data) | Data that has been manipulated or modified. |
| Cohort | A group of participants recruited into a study at the same time. |
| Confidential data (pseuodonymization, coded data, indirectly identifiable) | The status of this data is protected. Personally identifiable information (PII) in your data has been removed and names are replaced with a code and the only way to link the data back to an individual is through that code. The identifying code file (linking key) is stored separate from the research data. |
| Confidentiality | Confidentiality concerns data, ensuring participants agree to how their private and identifable information will be managed and disseminated. |
| Control (business as usual) | The individual or group does not receive the intervention. |
| Cross-sectional | Data is collected on participants for a single time point. |
| Data (research data) | The recorded factual material commonly accepted in the scientific community as necessary to validate research findings. (OMB Circular A-110) |
| Data Type (measurement unit, variable format, variable class) | A classification that specifies what types of values are contained in a variable and what kinds of operations can be performed on that variable. Examples of types include numeric, character, logical, or datetime. |
| Database (relational database) | An organized collection of related data stored in tables that can be linked together by a common identifier. |
| Dataset (dataframe, spreadsheet) | A structured collection of data usually stored in tabular form. A research study usually produces one final dataset per entity/unit (ex: teacher dataset, student dataset). |
| De-identified data (anonymized data) | Identifying information has been removed or distorted and the data can no longer be re-associated with the underlying individual (the linking key no longer exists). |
| Derived data | Data created through transformations of existing data. |
| Direct identifiers (PII, PHI) | These identifiers can directly identify a participant and should always be removed from research study data. There should be no need to keep these identifiers for analysis (i.e. name, email, address). |
| Directory (file structure, file tree) | A cataloging structure for files and folders on your computer. |
| Experimental data | Data collected from a study where researchers randomly introduce an intervention and study the effects. |
| Extant data | Existing data sources created from external to the research team/study. |
| File formats | Education research data is typically collected in one of three file formats: text( .txt, .pdf, .docx), tabular (.xlsx, .csv, .sav) , multimedia (.mpeg, .wav). |
| Identifiable data | Data that includes personally identifiable information. |
| Indirect identifiers | Even though these identifiers are not necessarily uniquely tied to one individual (i.e., birthdate or place of birth), if combined, this information could indirectly identify a participant. Therefore this information should be managed before publicly sharing data. |
| Longitudinal | Data is collected on participants over a period of time. |
| Merge (join, link) | Combining datasets together in a side by side manner (matching on an identifier). |
| Missing data | Occurs when there is no data stored in a variable for a particular observation/respondent. |
| Observational data | Data collected from a study where researchers are observing the effect of an intervention without manipulating who is exposed to the intervention. This includes many formats that education researchers collect data with (ex: survey, observation, assessment). |
| Participant database (study roster, master list, master key, linking key, code key, key code, main list, identifiers dataset, crosswalk, record keeping, tracking, participant tracking) | This database, or spreadsheet, includes any identifiable information on your participants as well as their assigned study ID. It is your only own means of linking your confidential research study data to a participant’s true identity. It is also used to track data collected across time and measures as well as participant attrition. |
| Path (file path) | A string of characters used to locate files in your directory system. |
| Personally identifiable information (PII, PHI) | This includes direct information (e.g., name and email), as well as indirect information that, if combined with other variables, could identify a participant (e.g., full birthdate and county of residence). Under FERPA, additional PII, such as a district or school ID, should also be removed. Protected health identifiers (PHI) is a similar protected category of information. There are 18 HIPAA protected health identifiers that should be removed from data in order to meet the Safe Harbor de-identification method (e.g., name, email, address). |
| Primary data (original data) | First hand data that is generated/collected by the research team as part of the research study. |
| Privacy | Privacy concerns people, ensuring they are given control to the access of themselves and their information. |
| Private data | Highly restricted data with limited access (i.e. passwords) |
| Qualitative data | Non-numeric data typically made up of text, images, video, or other artifacts. |
| Quantitative data | Numerical data that can be analyzed with statistical methods. |
| Randomized controlled trial (RCT) | A study design that randomly assigns participants to a control or treatment condition. In education research you often hear about two types of RCTs. The first being the Individual-Level Randomized Controlled Trial (I-RCT) in which individuals (such as students) are randomized directly to the treatment or control group. The second is a Cluster Randomized Controlled Trial (C-RCT), sometimes also called group-randomized, in which clusters of students (such as classrooms) are randomized. |
| Raw data | Unprocessed data collected directly from a source. |
| Replicable | Being able to produce the same results if the same procedures are used with different materials. |
| Reproducible | Being able to produce the same results using the same materials and procedures. |
| Research | The Common Rule definition of research is a systematic investigation, including research development, testing, and evaluation, designed to develop or contribute to generalizable knowledge. |
| Secondary data (extant data) | Existing data generated/collected by external organizations such as governments at an earlier point in time. |
| Sensitive data | Private information that could cause harm and should be protected from unwarranted disclosure |
| Simulation data | Data generated through imitations of a real-world process using computer models. |
| Standardization | Developing a set of agreed upon technical standards and applying them within and across all research projects. |
| Study | a single funded research project resulting in one more more datasets to be used to answer a research question. |
| Study ID (participant ID, location ID, site ID, unique identifier (UID), subject ID, participant code, record id) | This is a numeric or alphanumeric identifier that is unique to every participant, site or object in order to create confidential and de-identified data. These identifiers allow researchers to link data across time or measure. |
| Subject (case, participant, site, record) | A person or place participating in research and has one or more piece of data collected on them. |
| Syntax (code, program) | Programming statements written in a text editor. The statements are machine-readable instructions processed by your computer. |
| Treatment (experiment) | The individual or group receives the intervention. |
| Variable (column, field, question) | Any phenomenon you are collecting information on/trying to measure. These variables will make up columns in your datasets or databases. |
| Variable name (header) | A shortened symbolic name given the variable in your data to represent the information it contains. |
| Wave (time period, time point, event, session) | Intervals of data collection over time. |
2.6 The Research Life Cycle
The remainder of this book will be organized into chapters that dive into phases of the research data life cycle. It is imperative to understand this research life cycle in order to see the flow of data through a project, as well as to see how everything in a project is connected. If phases are skipped, the whole project will suffer.
You can see in Figure 2.1, how throughout the project, data management roles and project coordination roles work in parallel and collaboratively. These teams may be made up of the same people or different members, but either way, both workflows must happen and they must work together.
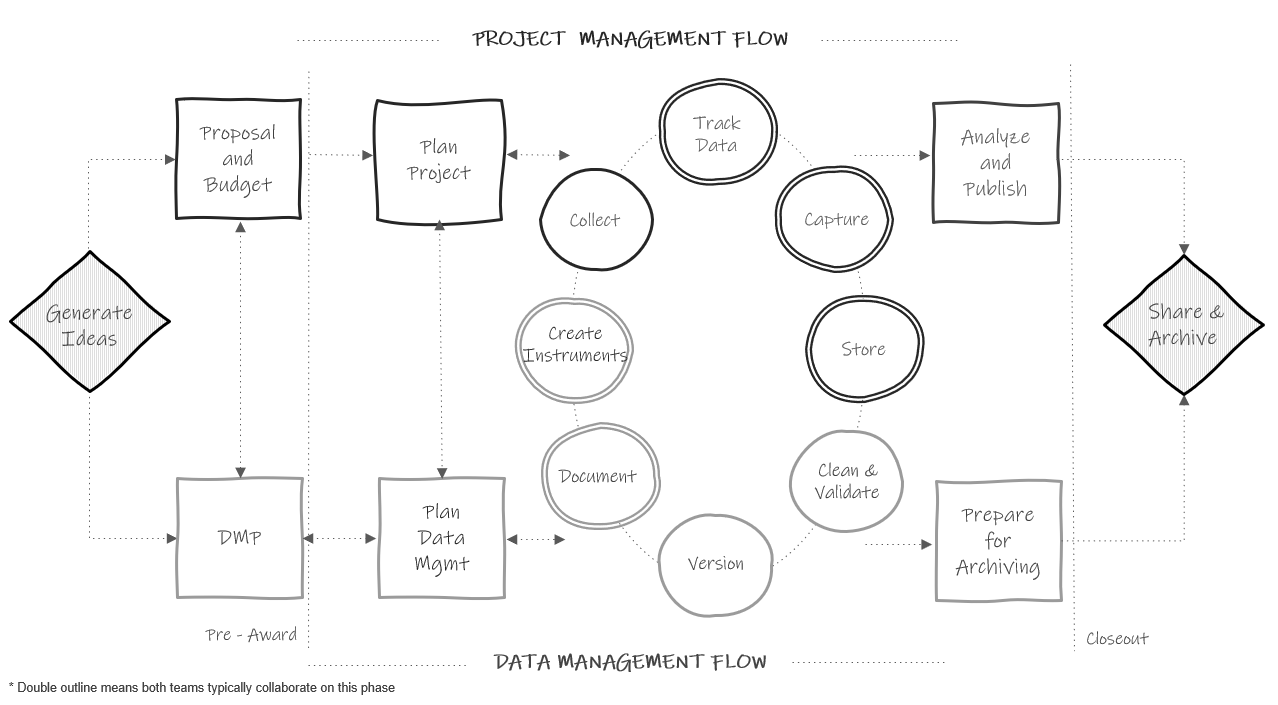
Figure 2.1: The research project life cycle
Let’s walk through this chart.
- In a typical study we first begin by generating ideas, deciding what we want to study.
- Then, most likely, we will look for grant funding to implement that study. This is where the two paths begin to diverge. If the team is applying for federal funding, the proposal and budget are created in the project management track, while the supplemental required data management plan (see Chapter 4) is created in the data track. Again, it may be the same people working on both of these pieces.
- Next, if the grant is awarded, the project team will begin planning things such as hiring, recruitment, data collection, and how to implement the intervention. At the same time, those working on the data team will begin to plan out how to specifically implement the 2-5 page data management plan submitted to their funder and start putting any necessary structures into place.
- Once planning is complete, the team moves into the cycle of data collection. It is called a cycle because if your study is longitudinal, every step here will occur cyclically. Once one phase of data collection wraps up, the team re-enters the cycle again for the next phase of data collection, until all data collection is complete for the entire project.
- The data management and project management team begin the cycle by starting documentation. You can see that this phase occurs collaboratively because it is denoted with a double outline. Both teams begin developing documentation such as data dictionaries and standard operating procedures.
- Once documentation is started, both teams collaboratively begin to create any necessary data collection instruments. These instruments will be created with input from the documentation. During this phase the teams may also develop their participant tracking database.
- Next, the project management team moves into the data collection phase. In addition to actual data collection, this may also involve preliminary activities such as recruitment and consenting of participants, as well as hiring and training of data collectors. At this point, the data management team just provides support as needed.
- As data is collected, the project team will track data as it is collected in the participant tracking database. The data management team will collaborate with the project management team to help troubleshoot anything related to the actual tracking database or any issues discovered with the data during tracking.
- Next, once data is collected, the teams move into the data capture phase. This is where teams are actively retrieving or converting data. For electronic data this may look like downloading data from a platform or having data sent to the team via a secure transfer. For physical data, this may look like teams entering paper data into a database. Oftentimes, this again is a collaborative effort between the project management team and the data team.
- Once the data is captured, it needs to be stored. While the data team may be in charge of setting up and monitoring the storage efforts, the project team may be the ones actively retrieving and storing the data.
- Next the teams move into the cleaning and validation phase. At this time the data team is reviewing data cleaning plans, writing data cleaning scripts, and actively cleaning data from the most recent data collection round.
- And last, the data team will version data as it is updated or errors are found.
- The teams then only move out of the active data collection phase when all data collection for the project is complete. At this time the project team begins analyzing study data and working on publications as well as any final grant reports. They are able to do this because of the organized processes implemented during the data collection cycle. Since data was managed and cleaned throughout, data is ready for analysis as soon as data collection is complete. Then, while the project team is analyzing data, the data team is doing any additional preparation to archive data for public sharing.
- Last, as the grant is closing out, the team submits data for public sharing.
As you work through the remaining chapters of this book, this chart will be a guide to navigating where each phase of practices fits into the larger picture.