16 Data Sharing
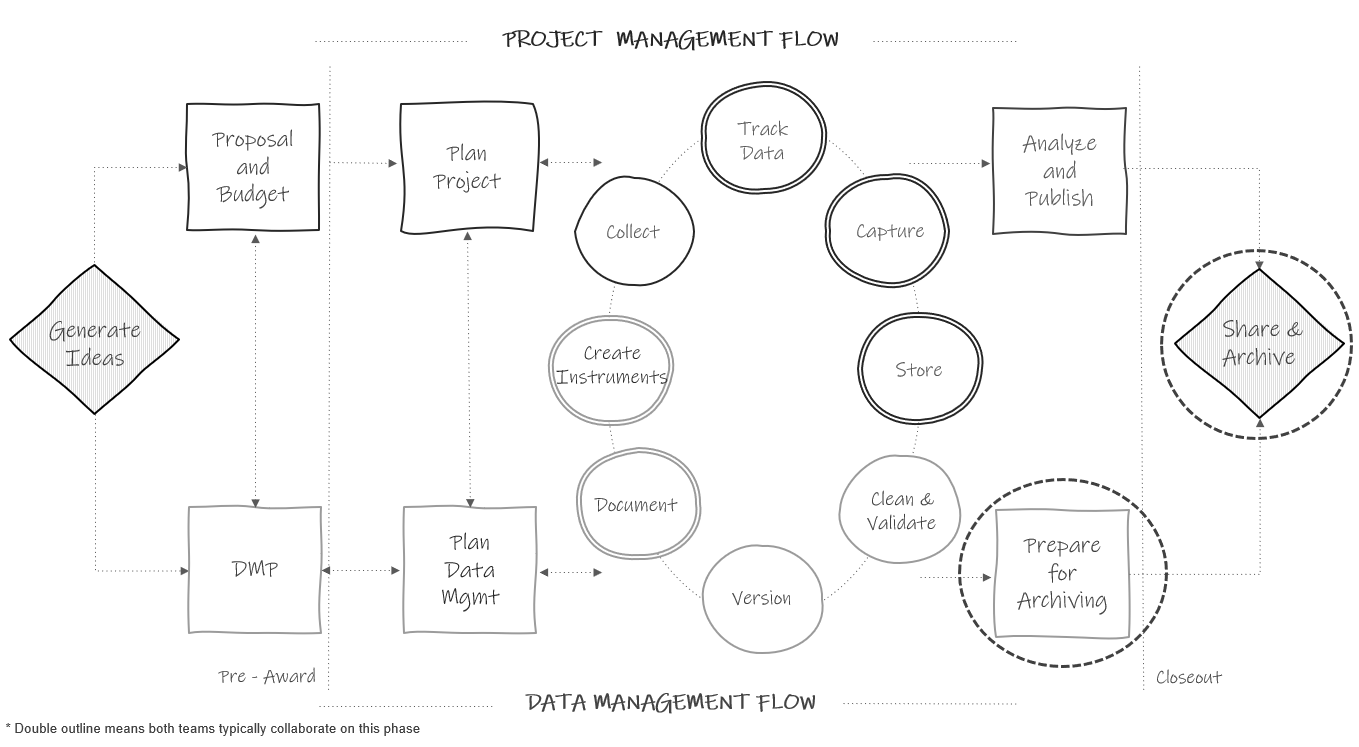
Figure 16.1: Data sharing in the research project life cycle.
Throughout a project, teams are internally sharing data and materials with a variety of people (e.g., team members, collaborators, funders) who use that information for a variety of purposes (e.g., analyses, reports, to answer questions). Yet, at the end of a project, or possibly earlier, it’s important for researchers to also consider making their research data available for broader public use (see Figure 16.1). However, publicly sharing project data and materials requires a lot of consideration. In this chapter we will first review reasons why you should publicly share your data, and then we will work through a series of decisions to make before sharing your data.
16.2 Data sharing flow chart
There is a series of decisions to be made when sharing your data (see Figure 16.2). While in some cases data sharing may not occur until the end of your project, many of your data sharing decisions will actually need to be made at the beginning of your project, when you write your data management plan (DMP) (see Chapter 5). These decisions will inform both your workflow during your active project and the steps you need to perform when preparing your data for archiving.
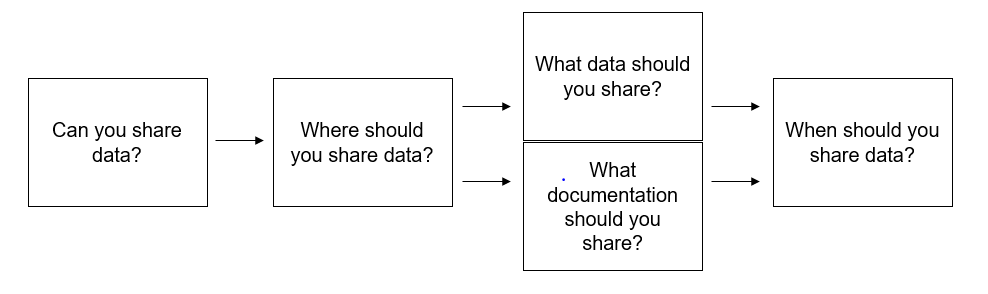
Figure 16.2: Decisions to be made before publicly sharing study data.
In this section we will walk through the flow chart, discussing what information is needed to make decisions as well as best practices associated with each decision.
16.2.2 Where to share?
Once you’ve decided that you are able to share data, either publicly or in a more restrictive manner, you then need to decide where you want to share data. There are many options for sharing your data, with some options being better than others. In most situations, the best option for sharing data will be a public data repository. This may be a repository chosen by you, or it may be a repository designated by a funder or other organization supporting your work. There are many benefits to sharing in a public repository (Neild, Robinson, and Agufa 2022; UK Data Service 2023).
- It meets the FAIR principles of making your data both findable and accessible (Section 2.4.1).
- It is the preferred method of data sharing for many supporters (e.g., NIH, IES) and it may be required by others (e.g., NIJ, NIMH, journals such as AMPPS).
- It provides a hands-off approach to data sharing, reducing the burden of maintaining your data and responding to data requests long-term.
- It provides a means to securely share restricted-access data if necessary.
- Even if you are not able to directly deposit the restricted-use data in a repository (e.g., the repository does not accept restricted-use data, an agency partner requires data to be stored at their site), repositories still support the creation of metadata-only records, which facilitate discovery of your data while still allowing sensitive data to be maintained and shared through the owner’s chosen data request system (Gonzales, Carson, and Holmes 2022; Logan, Hart, and Schatschneider 2021).
- Repositories provide support for data sharing, either through direct data curation services or by offering detailed guidelines on what to share.
However, due to supporter requirements (e.g., agency partner, institution, funder, journal), or other legal, technical, or ethical reasons, there may be a reason to share some or all of your data in other ways. The following are alternative ways to share your data (Alston and Rick 2021; Briney 2015; Klein et al. 2018; Neild, Robinson, and Agufa 2022; UK Data Service 2023).
- Deposit your data with an institutional archive.
- While this method provides the benefits of reducing the burden on your staff and securely storing your data, this option is not available at all academic institutions and these repositories may provide less service offerings than a public repository. Furthermore, data stored in an institutional archive, as opposed to a public repository, may be less findable for researchers outside of your institution.
- Deposit with a partner agency.
- In some cases, data sharing may only be allowed if you deposit the data with an agency that you partnered with for the study (e.g., a school district). In this case, all data requests will go through that partner.
- Supplemental materials attached to an article or stored on a publisher’s website.
- A concern with this method is that materials will be lost if a journal changes publishers or a publisher changes its website.
- Share through a lab, personal, or project website.
- Using this method you may allow participants to freely download datasets from the site, or they may be required to go through an application process first before accessing data.
- While this system provides some accessibility, it requires a significant commitment from your team. Sharing in this way requires to you publicize your site to increase visibility, as well as commit the resources to building and maintaining a secure and reliable data sharing pipeline. Furthermore, websites change and links break, reducing the long-term accessibility of your data.
- Informal peer-to-peer sharing.
- Here data owners share data with peers on an as-needed basis. While this method may work fine for peers, it doesn’t make a broader audience aware of the availability of your data and keeps the burden of data maintenance and responding to requests on you and your staff.
- This type of sharing is often synonymous with using a “data available upon request” statement in a publication. While these statements do make broader audiences aware of your data, there are several studies that have found that these data availability statements rarely result in access to data (Stodden, Seiler, and Ma 2018; Vines et al. 2014). A better alternative is to already have data shared in a location and direct people to that system (e.g., link to a repository).
Figure 16.3, modified from a flow chart created by Borghi and Van Gulick (2022), can help you work through the process of choosing where to share each data source. Ultimately though, no matter where you choose to share your data, it is important to make this decision early on because it will impact many of the other decisions that need to be made. In particular, if you choose to deposit data in a repository, you will want to review repository-specific requirements and standards to make sure they are accounted for in your DMP (e.g., data format requirements, metadata standards used) and in your data management processes throughout the study. Making this decision early on also allows you to begin creating a schedule for ongoing data deposits throughout your study if that is something you want to consider doing, or if it is required by your funder or other supporter (ICPSR 2020).
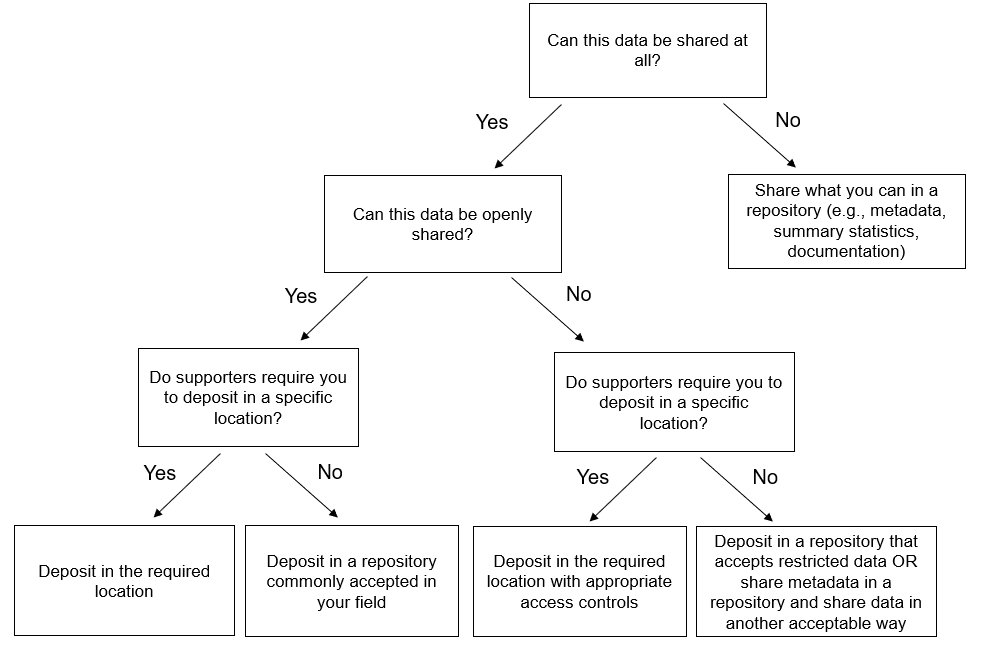
Figure 16.3: A series of decisions to make when deciding where to share data.
16.2.2.1 Choosing a repository
At this point, you may be ready to choose a repository to share your data in. There is an abundance of available data repositories to choose from and the Registry of Research Data Repositories (re3data.org) has indexed repositories, allowing researchers to search the vast landscape of options. Several agencies have also shared criteria to help you narrow your choices. Both the National Institutes of Health (2023b) and the National Science and Technology Council (2022) have released desirable characteristics for data repositories, and the Institute of Education Sciences has also provided its own set of dimensions to review when considering an appropriate repository (Neild, Robinson, and Agufa 2022). While each of these agency lists should be reviewed, the following questions are a starting point for choosing a repository that fits the needs of your project (Briney 2015; Gonzales, Carson, and Holmes 2022; Goodman et al. 2014; Klein et al. 2018).
- Is a specific repository required by your supporter (e.g., funder, journal, institution)?
- If yes, you don’t need to proceed any further, this is the repository you should share your data in. If the required repository does not meet your specific needs (e.g., you want to reach a specific audience), you can always share metadata in another repository and link to the repository where your data is shared.
- If a specific repository is not required, also check to see if your supporter has a preferred list of repositories. If they do, it may be best to narrow your search to the recommended options.
- Is a domain-specific repository available (i.e., caters to your field or specific data type) or are there generalist repositories that are commonly accepted in your field?
- Domain-specific repositories may be of more interest to researchers in your field and may be the best option to help facilitate discovery of your datasets. Using a domain-specific repository can also help ensure that you are preserving data according to recognized standards in your field. At minimum though, using generalist repositories that are common in your field improves discoverability.
- A few domain-specific repositories commonly used in the field of education research include ICPSR (https://www.icpsr.umich.edu) and LDbase (https://www.ldbase.org/).
- NIH has also established the Generalist Repository Ecosystem Initiative (GREI), which consists of established generalist repositories that support FAIR principles and are collaborating to develop a standard set of services and structures. Generalist repositories in this ecosystem that are commonly used in education research include OSF (https://osf.io), Zenodo (https://zenodo.org/), and Figshare (https://figshare.com/).
- If you have qualitative data, there are also repositories specifically designed for this type of data, such as the Qualitative Data Repository (https://qdr.syr.edu/).
- Does the repository allow varying access levels?
- Can de-identified data be easily accessed by a wide audience?
- What are the access options (e.g., download)?
- Are users required to have an account to access data?
- Are restricted-use files accepted?
- Is there a transparent process for reviewing data access requests? Who reviews access requests?
- How are users able to access restricted-use data files (e.g., secure download, virtual data enclave, physical data enclave)?
- Can de-identified data be easily accessed by a wide audience?
- Is there a cost associated with using the repository?
- Consider both costs to store your data and costs for users to access your data. There may also be costs associated with additional services such as data curation.
- What are the allowable file formats and sizes?
- Check size limits for both data files and the entire project. Also check which file formats are allowed. Certain repositories may have file format preferences for both data files and documentation files.
- You’ll also want to make sure that the repository provides files back to users in commonly accepted formats, including at least one non-proprietary format.
- Does the repository have long-term sustainability?
- Make sure to review the repository’s data retention policies to ensure it meets your requirements.
- You’ll also want to ensure that the repository has a plan for long-term management of data (considering both funding and infrastructure).
- Does the repository have linking capabilities?
- Does the repository allow you to link to projects, publications, code, or data stored on external sites?
- Are clear use guidelines provided?
- Is there clear guidance on how data can be used? Does the repository allow you to add usage licenses?
- Licenses set clear terms of use for data. Commonly used license groups include Creative Commons licenses (https://creativecommons.org/) and Open Data Commons licenses (https://opendatacommons.org/). The most commonly used licenses are CC BY and ODC-By which allow others to freely reuse materials as long as they cite the original creator.
- Are you able to set different reuse conditions for different datasets?
- Is there clear guidance on how data can be used? Does the repository allow you to add usage licenses?
- Is metadata collected upon deposit?
- Does the repository collect comprehensive metadata, and does it use standards that are appropriate for your field?
- Does the repository assign unique persistent identifiers?
- Unique persistent identifiers (PIDs), such as digital object identifiers (DOIs), provide an enduring reference to a digital object, even if the object’s URL changes. Repositories that assign PIDs support discoverability as well as allow researchers to track the use and contributions of their datasets.
- Does the repository track data provenance?
- It is important to have the ability to freely update and remove data as needed.
- When data is amended, does the repository record data provenance by versioning materials and assigning updated PIDs?
- Are curation and quality assurance services available?
- Does the repository provide curation services to ensure that data is de-identified, high quality, in interoperable formats, and shared with appropriate metadata?
- Does the repository measure reuse?
- This includes things like tracking number of downloads and tracking citations.
- Does the repository have appropriate security measures in place?
- This includes measures for both the security of the data itself (e.g., maintaining backups) and measures to ensure participant privacy (e.g., ensuring only authorized users are able to access restricted data).
Resources
16.2.3 What data to share
The requirements for what data should be shared will most likely vary depending on your supporting agency. As an example, NIH asks researchers to share their final research data which includes any “recorded factual material commonly accepted in the scientific community as necessary to validate and replicate research findings, regardless of whether the data are used to support scholarly publications” (National Institutes of Health 2023c).
Even if your supporter does not require this broad sharing, in general this is still a good policy to follow. At the end of your study, share all of the data collected and captured for the project, while minding any legal, ethical, and technical reasons that you cannot share some information. With the exception of identifying information, this includes sharing all primary data collected through the project, both raw (item-level) and derived variables, as well as any secondary data captured and linked to your sources (e.g., student education records) (ICPSR 2020).
Before sharing, review any existing agreements or licenses associated with each data source to ensure you are allowed to share and in what format you are allowed to share. Also review any applicable consent agreements. You will not want to share any data outside of the scope of what participants agreed to. Last, before sharing item-level data, review copyright for published scales to see what is allowed. Some publishers may only allow you to share derived scores (Logan 2021).
16.2.3.1 Processing of files
As discussed in Chapter 14, there are three levels of data files, raw, clean, and analytic. When publicly sharing project data, it’s often best to not share your raw datasets. This may seem counterintuitive to ideas of transparency and reproducibility, but in education research these raw datasets often contain identifiable information, and despite our best efforts to collect comprehensible data, they typically do not meet our data quality criteria. They tend to still require some sample cleaning (e.g., removing duplicates), as well as some variable renaming, recoding, or other transformations to ensure that data are not misused or misinterpreted by future researchers.
Instead, it is more useful to share the general clean datasets discussed in Chapter 14. These datasets have all direct identifiers removed (indirect identifiers discussed in Section 16.2.3.4), they have been curated to allow for easier interpretation of variables, and they contain all of the information necessary to validate any research findings. In the same repository, it is also possible to share any analytic datasets created that will allow replication of findings in any specific reports or publications.
16.2.3.3 File formats
Most funders require data to be shared in an electronic format, and for quantitative data in particular, that usually means a rectangular format. In keeping with FAIR principles (Section 2.4.1), it is recommended to provide data in at least one non-proprietary format (see Table 15.1 for example formats). As discussed in Chapter 13, this not only allows a broader audience to access your data, but also protects against technological obsolescence.
However, as covered in Chapter 14, it can be beneficial to also share data in formats that have embedded metadata (e.g., SPSS, Stata). Providing your data in both a non-proprietary format and a proprietary format that is widely used in the field, can give your users options while also protecting your data from obsolescence (Institute of Education Sciences 2023a; Neild, Robinson, and Agufa 2022).
Most importantly, though, if sharing in a repository, check to see if there are any data format requirements. ICPSR, for example, encourages submission of files with embedded metadata, such as SPSS, Stata, or SAS files (ICPSR 2023b). They then use these files and curate them into ASCII data with setup files to accompany statistical programs. As another example, the National Archive of Criminal Justice Data used by the National Institute of Justice (NIJ) prefers SPSS formats for quantitative data, but will also accept Stata or SAS files (National Archive of Criminal Justice Data 2023).
16.2.3.4 Assess disclosure risk
Before publicly sharing study data, it is imperative that you conduct a disclosure risk assessment. In conducting this assessment, review variables that could potentially identify a participant, either directly or indirectly, and also review sensitive variables that have the potential to cause harm to participants if their identity is disclosed.
- Direct identifiers
- As discussed in Chapter 4, these are identifiers that are unique to an individual and can be used to directly identify a participant (e.g., name, email, IP address, student ID). It can be helpful to mark these identifiers in your data dictionary early on to keep track of what should be removed. If you are unsure exactly what direct identifiers to check for, the 18 protected health identifiers listed in the HIPAA safe harbor de-identification method 88 are a good starting point. FERPA 89 also provides a list of personally identifiable information (PII) to review.
- Indirect identifiers
- While our dataset may be technically de-identified after removing our direct identifiers, it is still important to consider the possibility of deductive disclosure (Institute of Education Sciences 2023a). Research has shown that it is possible to re-identify someone through a combination of indirect identifiers (Sweeney 2002) (see Table 4.1 for examples). Further care must be taken to consider if there are any other ways participants can potentially be re-identified in our data. This includes considering the following.
- Open-ended questions: These variables may contain information that can directly or indirectly identify individuals.
- Outliers: If someone has extreme values for a variable, it may be easier to identify that individual.
- Small cell sizes: If there is only one person who took a survey on a particular date, or only one person who fits in a specific demographic category, it is easier to re-identify that individual. The NCES Standard 4-2-10, suggests that all categories have at least three cases to minimize risk (Seastrom 2002), while others may recommend more stringent requirements such as a minimum of five cases (Schatschneider, Edwards, and Shero 2021).
- Combinations of variables, or crosstabs, can also create small cell-sizes (e.g., a student may be identifiable by school size + special education status + gender + grade level). Generally, the more indirect identifiers you have in your dataset, the more possible combinations exist, increasing the risk of re-identification (Morehouse, Kurdi, and Nosek 2023).
- When reviewing this information, consider not only information that the general public may be able to decipher, but also what information may be known to people who know a participant (e.g., administrator, teacher, parent). You also want to consider the amount of potentially publicly available information about a participant or site (e.g., administrative datasets, social media data) and the likelihood that public information could be used to re-identify someone (i.e., by linking public data with your study data) (Filip 2023; Meyer 2018; Neild, Robinson, and Agufa 2022).
- While our dataset may be technically de-identified after removing our direct identifiers, it is still important to consider the possibility of deductive disclosure (Institute of Education Sciences 2023a). Research has shown that it is possible to re-identify someone through a combination of indirect identifiers (Sweeney 2002) (see Table 4.1 for examples). Further care must be taken to consider if there are any other ways participants can potentially be re-identified in our data. This includes considering the following.
- Sensitive information
- In assessing disclosure risk, you also want to review any variables that could cause potential harm to an individual if they were re-identified. Examples of these variables include health information, special education status, disciplinary status, or information on risky behaviors (Morehouse, Kurdi, and Nosek 2023; Neild, Robinson, and Agufa 2022).
16.2.3.4.2 Sharing controlled access data
If you find that de-identifying your data alters it in a way that distorts data quality or structure, or if you believe that the risks of sharing your data are still more than minimal, you should consider sharing in a controlled manner (ICPSR 2020; Meyer 2018; Morehouse, Kurdi, and Nosek 2023; Neild, Robinson, and Agufa 2022; Schatschneider, Edwards, and Shero 2021). As discussed in Section 16.2.1, it is still possible to share these files through restricted access. In a repository these files can be shared through means such as secure downloads, virtual data enclaves, or even onsite data enclaves. Access to these restricted data is permitted only through an application process where requestors complete a detailed data use agreement. See Figure 16.4 for an example of a restricted access dataset available from the United States Department of Health and Human Services. Administration for Children and Families, Office of Planning, Research and Evaluation (2023) in the ICPSR data repository.
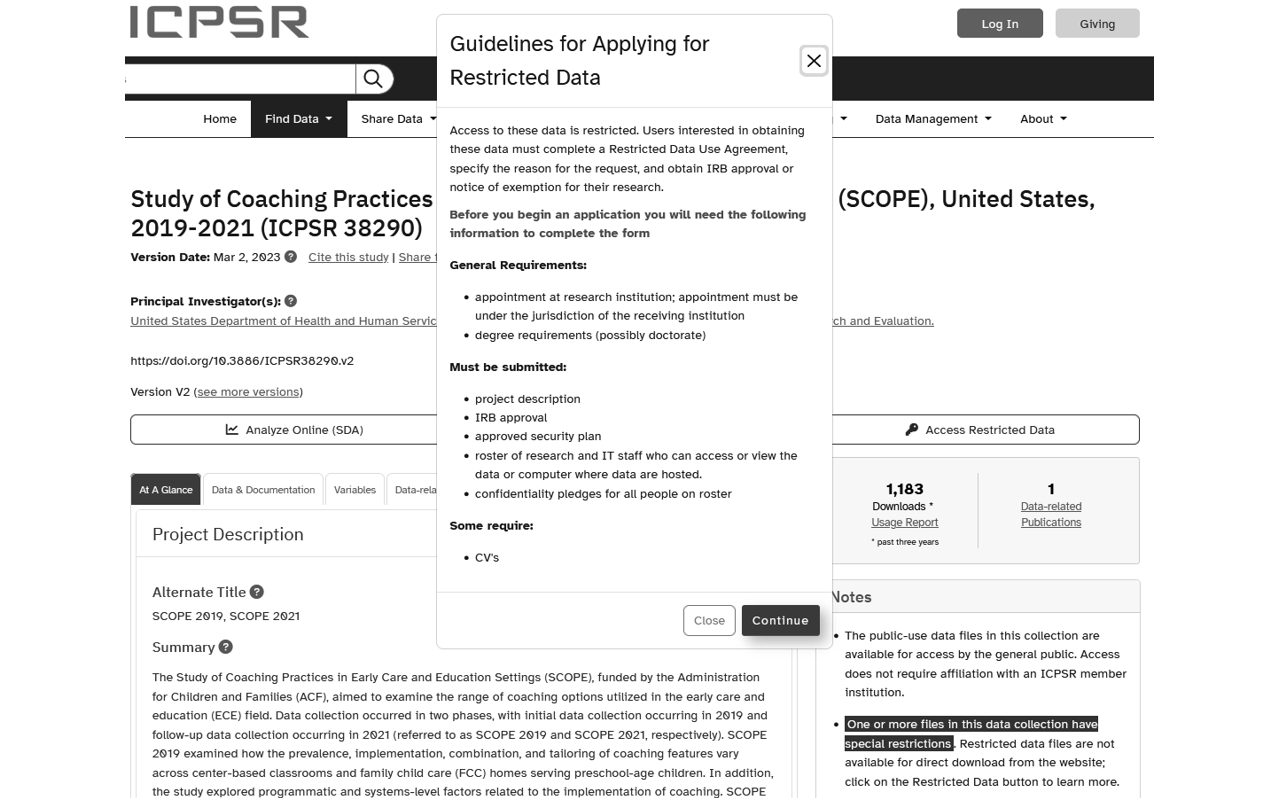
Figure 16.4: An example of restricted access data on ICPSR
If you are using a repository that does not accept restricted data, you can still share metadata in a repository, along with information for users to contact you about requesting access to restricted-use data that you share through your own personal system. No matter where you share data, in order to maximize public benefit, you should still consider openly sharing some data. That may simply be summary statistics (e.g., means, standard deviations) provided in tables. Or it could involve sharing two sets of files. For example, a public access version of a file with sensitive variables removed/altered and a restricted-use version of the same file with sensitive variables retained. However, be sure to consider all possible disclosure risks before sharing to ensure that someone with access to both the restricted and public files are not able to identify individuals. Also make sure that no inconsistencies between files are created during this process (ICPSR 2020; Logan, Hart, and Schatschneider 2021; Neild, Robinson, and Agufa 2022; Schatschneider, Edwards, and Shero 2021) .
16.4 Roles and responsibilities
As with every phase in the research life cycle, it is so important to assign roles and responsibilities throughout this process. Make a checklist of everything that needs to happen in this data sharing process and assign someone to every task. Many of the required tasks (e.g., data cleaning, documentation) should not require additional planning, as those roles and responsibilities are designated in other phases. However, there are several new tasks that will be specific to this phase (e.g., creating data use agreements, assessing disclosure risk), and some tasks will vary depending on if you are sharing through a repository/institutional archive (e.g., communicating with repository staff, troubleshooting issues) or sharing on your own (e.g., developing a data request and sharing system). Even after data has been shared, depending on how and where your data is shared, you may also need to assign responsibilities for ongoing maintenance (e.g., responding to access requests).
As you begin assigning roles, you may discover that additional expertise is needed, especially for things like the data de-identification process or developing data sharing agreements. If yes, also begin looking into who may fill these gaps (e.g., research data librarians, methodologists, data curation specialists at your repository). Once your data sharing plan is formalized, it should be documented in all necessary locations (e.g., DMP, research protocol, SOPs, informed consent forms).
A few organizations have put together data sharing checklists. These checklists may help you begin assigning team members to specified responsibilities.
Resources
16.5 Revisions
When publicly sharing study data and materials, researchers are often concerned that errors may be found (Beaudry et al. 2022; Houtkoop et al. 2018; Levenstein and Lyle 2018). If errors are found in your data after publicly sharing, while not ideal, it is important to recognize that you are not the first person this has happened to. Other researchers have come across errors in their data after sharing and have successfully made plans for addressing the problem (Aboumatar et al. 2021; Grave 2021; Laskowski 2020; Strand 2020). Depending on how you’ve shared and used your data, there are different ways to address these errors.
First, if you have used your data in a publication, contact your journal to make them aware of the errors you found. The journal may provide options, including the opportunity to revise or retract your article. Next, you will want to update your shared data.
If your data is shared in a repository or institutional archive:
- Make the appropriate edits to your data and upload the new version to your repository.
- Many repositories will then assign your project, or data, a new version number, along with a new DOI, to denote the changes in the project.
- If the repository does not provide a place to note the reason for revisions, add this information in your own changelog or README in the project folder (Kopper, Sautmann, and Turitto 2023b; Towse, Ellis, and Towse 2021).
- If the repository requires/allows users to make an account before accessing the data, they may have a system to email current users to let them know that a new version of the data has been created .
If your data is not in a repository or institutional archive:
Make the appropriate edits to your data and save as a new version. Make a note about the change in your internal changelog.
Then, consider personally reaching out to anyone who has submitted a data request to notify them of the errors in the data.
While the potential for others to find errors is often viewed as a consequence to data sharing, we can also view this as an opportunity to do better science. Giving others the chance to catch errors in our data, that we may not have otherwise caught (Bishop 2014; Klein et al. 2018; Schoen and Solmaz-Ratzlaff 2023) allows us to make corrections, ensuring that our findings are not derived based on inaccurate data. Data sharing also provides incentive for us to implement more rigorous data management practices that hopefully improve data integrity and create less concern for future errors (Klein et al. 2018; Strand 2021).