17 Additional Considerations
Up until this point, we have mostly focused on a workflow for one team with one project. However, it is common for projects to include multi-site collaborations (e.g., a grant shared across multiple research institutions), and for teams to have multiple projects. Both of these add complexity to data management which I will briefly address.
17.0.1 Multi-site collaborations
Multi-site, or multi-team, collaborations require additional planning around roles and responsibilities, workflows, and standards. Jumping into multi-site collaborations without spending time cross-team planning often leads to unfortunate data security, quality, and usability concerns. Before a project begins, consider documenting expectations in a collaboration agreement. When developing this type of agreement, review everything in a typical data management checklist but come to an agreement on decisions. The following types of multi-site issues should also be addressed (Briney 2015; Schmitt and Burchinal 2011).
- How will teams maintain consistency in procedures across sites (e.g., shared SOPs, shared style guides, oversight of practices)?
- If each site is handling its own data tracking, capture, entry, and cleaning procedures, it is imperative that these processes are standardized to allow for datasets to be integrated.
- How will teams handle data ownership?
- What are the roles and responsibilities across sites?
- What tools will be used to allow for multi-site data tracking, collection, entry, storage, and sharing?
Documents, such as a RACI matrix (Miranda and Watts 2022), can help lay out expectations for team collaborations (Figure 17.1). In these charts, each site is assigned to a task as either responsible, accountable, consulted, or informed.
- Responsible: The site is responsible for completing this task.
- Accountable: The site provides oversight, ensuring the the task is completed with fidelity.
- Consulted: The site is always consulted before a decision is made on this task.
- Informed: The site is provided high-level information about decisions that are made.
Assigning levels of responsibility to each site allows collaborators to clearly see what is expected from them in a project. Within site tasks can then be further assigned to specific roles.
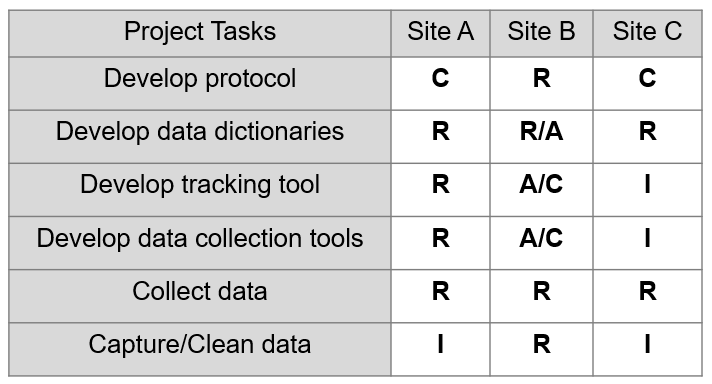
Figure 17.1: Example of a simplified RACI chart for a multi-site project collaboration
17.0.2 Multi-project teams
Similar to multi-site projects, organizing multiple projects within a team requires additional coordination. As your number of active projects grow, the sophistication of your operations should grow as well. Consider doing the following (Van den Eynden et al. 2011):
- Centralize resources.
- Create templates, SOPs, code snippets (reusable blocks of code), and style guides that can be used across projects. Utilize your team wiki to post shared resources in a central location where team members can easily access them (see Section 8.1.2). Centralizing resources reduces duplication of efforts, and also improves standardization, allowing you to more easily integrate data across projects.
- Encourage team science.
- When running multiple grants, the “lone cowboy” model of having just one person manage everything becomes even less feasible (J. H. Reynolds et al. 2014). Embrace the idea that it takes a team of people, skilled in many different areas (e.g., project management expertise, data management expertise, content expertise, administration expertise), to do quality research (Bennett and Gadlin 2012). With more than one grant, it is potentially more feasible to hire people to fill specialized roles, and to fund them across multiple grants.
- Create a hierarchy of roles.
- As the size of a team increases, it becomes important to assign someone to foster collaboration and oversee fidelity to data management standards across projects (Briney 2015). Create a hierarchy of roles, including data management implementers (e.g., data specialists, data managers) and supervisors (e.g., senior data managers, data leads), with the supervisor role helping to prevent internal drift through expectation setting, oversight, and mentorship.
- Create support systems.
- If your team is large enough, and you have multiple people working on data management across different projects, it may be helpful to create a data core. This internal group of data people can meet regularly to share knowledge and resources, develop and modify shared documentation, and develop internal data trainings for staff, increasing capacity for your center.
17.0.3 Summary
Collecting data is a bit like cooking a good meal. If you clean as you go, when you are full and sleepy you will have much less to do.
- Felicia LeClere (2010)
Slow science is often used to describe an antithesis to the increasingly fast pace of academic research, instead suggesting that science should be a slower, more methodical process (Frith 2020). Likewise, if we hurry a research project along without spending time putting quality data management processes into place, we increase the possibility that we end up putting research into the world that we cannot trust. Instead, we should take time to plan data management before a project begins, and implement quality practices throughout the life cycle. While it may be difficult to support this slow process early on, remember that data management gets easier the more you do it. Once you have templates, protocols, and style guides in place, those documents and processes can be reused, easing burdens in future projects (Levenstein and Lyle 2018).
There is no one-size-fits-all approach to data management though (Bergmann 2023; J. H. Reynolds et al. 2014). Projects are nuanced and there is no way to anticipate every way in which each specific project’s data needs to be managed. Instead, use the “buffet approach” and implement what works best for your project and your team (Bergmann 2023). What matters most is that those practices are implemented consistently within your project, and that ultimately they produce quality, well-documented, data products that are accepted in the field. Similarly, while it is possible that all of the practices mentioned in this book work for your project, it is unlikely that your team has the bandwidth to do it all. Instead, implement “good enough” practices that allow you to achieve the quality outcomes you desire (Borghi and Van Gulick 2022; Wilson et al. 2017). You don’t have to create all the documentation or use the most sophisticated data cleaning methods. You simply need to use methods that are good enough to reach your goals. Also make sure to periodically review your data management practices to ensure you are keeping up with changing requirements, technologies, standards, or team/project needs. Consider holding a data management retreat or workday once a year in order to have time set aside to review procedures as a team (Spinks 2024).
Last, as the awareness of the necessity of good data management grows in our field, we can only hope that systemic changes will continue to happen, making these efforts easier for education researchers. While institutions, such as academic libraries, provide data management learning opportunities including workshops, online modules, and on-demand courses, these resources are still not reaching everyone. Integrating data management content into required college coursework would improve data management practices for all the researchers who are out there “winging it” because they learned data management through informal methods. Funding institutions may also begin to find ways to necessitate data management training for applicants. With requirements for data management and sharing expanding, Wilson et al. (2017, 19) suggest that “it is unfair as well as counterproductive to insist that researchers do things without teaching them how”. Furthermore, developing shared standards for the field of education would do wonders in easing the burden on researchers who are having to make on the fly data management decisions, instead allowing them to follow a set of instructions for tasks such as formatting and documenting their data. Developing these standards would also benefit anyone interested in scientific inquiry, improving consistency in the quality and usability of publicly shared data products.